Search for...
Bookmarks by pm1e
Published Bookmarks


Are you taking the SAT Test? Think You Can Wing it? You cant. Find out why this expert says so. From traps to misconceptions, the SAT will catch you out.
Students are always looking for great note taking strategies. It just so happens we have 4 of the best. Have a look and let us know what you think

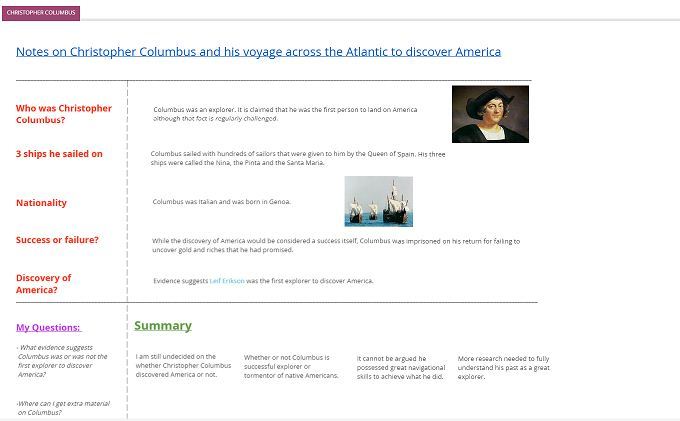
As October comes around, so too do a number of important dates on the American calendar. We found some great Flashcards on ExamTime to help celebrate Christopher Columbus, Alaska Day, Leif Erikson Day and Halloween.

We know that sticking to your learning plan can be difficult. Not any more. Check out my 5 tips on how to stay on track with your study goals this year.

As the first window of Praxis testing opens in the coming weeks, we decided to share some insights with you on to best to prepare
Did you know there are 6 different types of learners? Determining which type of learner you are can significantly boost your chances of performing better when it comes to exam time.
Submit Bookmark